Использование вложений в OpenAI Five
В этой статье я хотел бы сосредоточиться на одном аспекте архитектуры их сети - их изобретательном использовании вкраплений для обработки огромного и переменного количества входов и выходов политики

В то время как о OpenAI бот поведение и общее значение сообщество обсуждало, было на удивление мало технического анализа их методов обучения и архитектуры сети. Основным источником до сих пор является оригинальная запись в блоге OpenAI Five. В какой-то степени это оправдано - они использовали стандартный алгоритм PPO (изобретенный собственными силами пару лет назад) и проверенную схему обучения самостоятельной игре (также задокументированную в одной из их статей). Но в блоге есть легко упускаемая жемчужина - ссылка на их схему сетевой архитектуры.
В этой статье я хотел бы сосредоточиться на одном аспекте архитектуры их сети - изобретательном использовании вкраплений для обработки огромного и переменного количества входов и выходов политики. В то время как использование вкраплений и точечного произведения внимания является стандартной техникой в обработке естественного языка, они не так широко используются в обучении с подкреплением.
Обновление: после написания этой записи я узнал, что в одном из более поздних сообщений в блоге OpenAI есть более новая версия диаграммы сетевой архитектуры. Поскольку различий в использовании эмбеддингов было не так много, я решил не переделывать изображения и оставить анализ новой сети в качестве домашнего задания.
Что такое вкрапления?
В математике эмбеддинг означает отображение из пространства X в Y с сохранением некоторой структуры объектов (например, расстояния между ними). Однако использование эмбеддингов в контексте нейронных сетей обычно означает преобразование категориальных переменных (например, индексов слов) в непрерывные векторы. Передача индексов слов непосредственно в качестве входных данных сети сильно усложнила бы ее работу, поскольку ей пришлось бы придумывать бинарную характеристику для каждого значения индекса (при условии, что они не связаны между собой). Вместо этого мы помогаем сети и преобразуем категориальные значения в векторы one-hot. Если умножить вектор one-hot на матрицу весов, то он, по сути, выбирает заданную строку из матрицы весов. В deep learning toolkits этот шаг преобразования в one-hot вектор и умножения с весовой матрицей обычно пропускается, вместо этого мы используем индекс непосредственно для выбора строки из весовой матрицы, рассматривая ее как таблицу поиска. Наиболее важным аспектом является то, что векторы встраивания изучаются так же, как и весовая матрица с одноточечными векторами.

Наиболее известное применение вкраплений - обработка естественного языка, где индексы слов преобразуются в векторы слов (или вкрапления). Было показано, что когда сеть обучена предсказывать по вектору слова векторы окружающих его слов, векторы слов приобретают семантический смысл и с ними можно производить арифметические операции. Например, "женщина" - "мужчина" + "король" дает вектор, близкий к "королеве". Можно представить, что "женщина" - "мужчина" дает вектор гендерного переноса, а добавление его к "королю" преобразует его в женщину-правителя. Или, в качестве альтернативы, если представить это как "король" - "мужчина" + "женщина", то "король" - "мужчина" производит вектор "правитель", а добавление его к "женщине" производит "королеву".
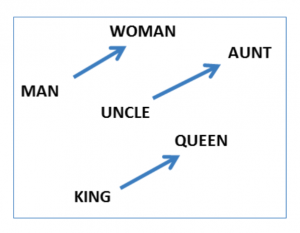
Image credit: Mikolov et al. 2013. Linguistic Regularities in Continuous Space Word Representations.
Сеть OpenAI Five
Прежде чем мы перейдем к конкретике, несколько слов об общей архитектуре сети.
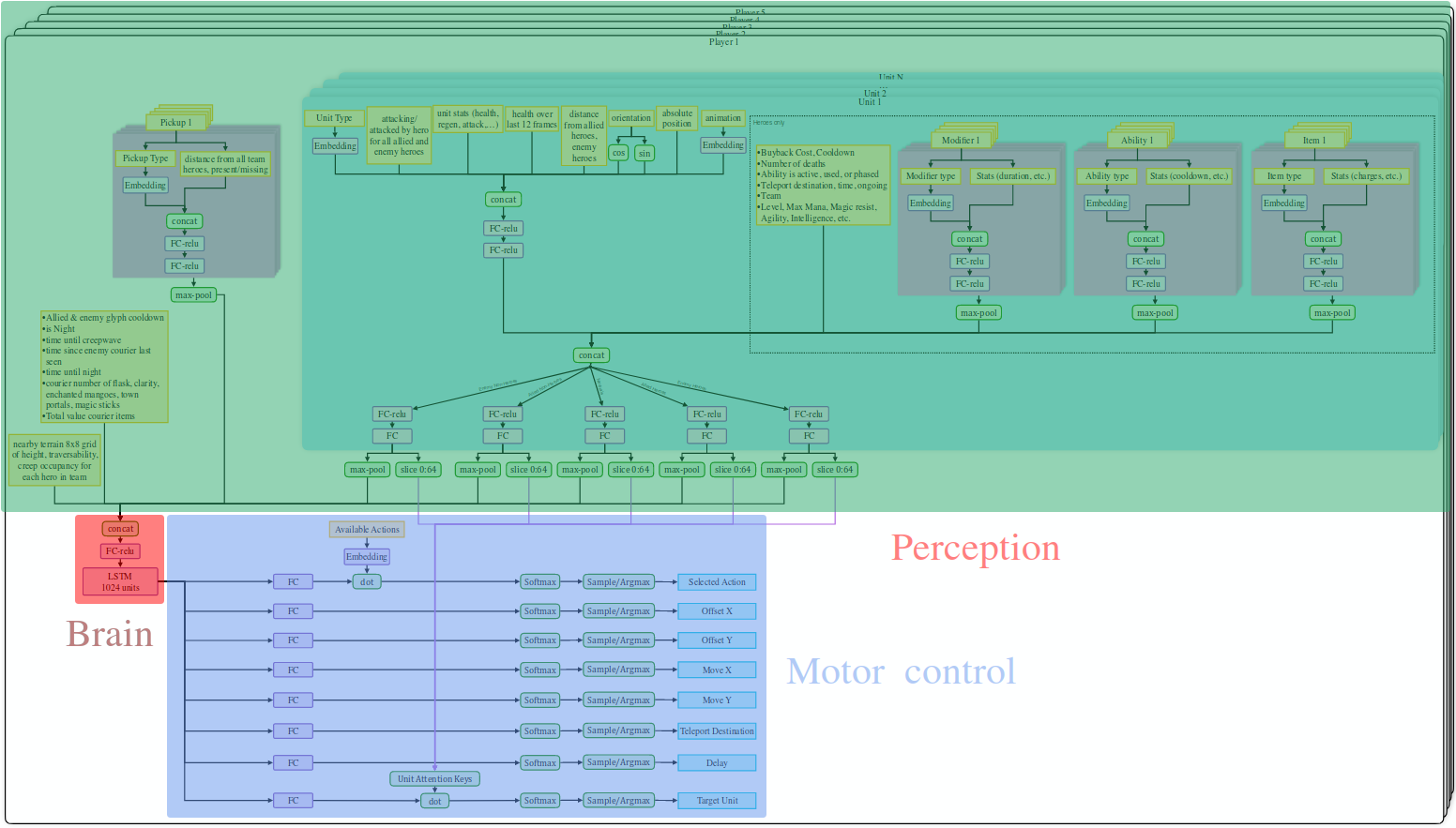
Image credit: OpenAI.
Каждый из пяти ботов имеет свою собственную сеть, со своими входами и действиями. (Не уверен, что параметры пяти сетей являются общими или нет). Единственное общение между ботами происходит через игру, я могу представить, что они делают что-то вроде танца пчелы, чтобы сообщить местоположение врага другим ботам, но я не думаю, что они действительно делают это, или даже нуждаются в этом. Обновление: В новой версии сети есть max-pooling над игроками, который можно рассматривать как однонаправленный широковещательный канал связи.
Верхняя часть сети на рисунке обрабатывает наблюдения. Она объединяет данные из различных источников и передает все в одну ячейку LSTM. Выход этой LSTM-ячейки используется нижней частью сети для выработки действий. В двух словах все просто - обрабатываем наблюдения, передаем их в LSTM и производим действия. Конечно, дьявол кроется в деталях, и именно это мы рассмотрим в следующих разделах.
Вкрапления в наблюдения
Боты OpenAI Five используют API Dota 2, чтобы "видеть" окружающие юниты и здания. В результате получается список юнитов переменной длины (геры, крипы, башни и т.д.) и их атрибуты. У OpenAI есть хорошие визуализации пространства наблюдения и пространства действий в их блоге, я рекомендую проверить их.
Image credit: OpenAI.
Следующая диаграмма суммирует обработку, применяемую к атрибутам одной единицы.
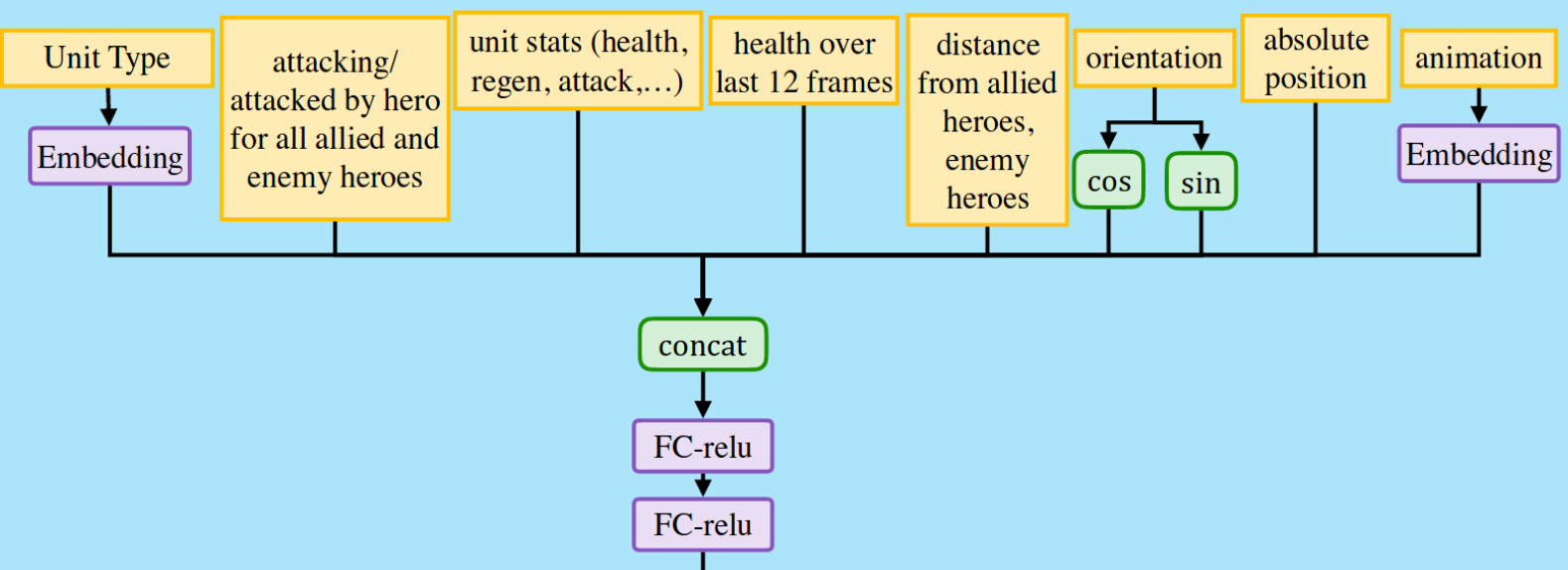
Image credit: OpenAI.
В левом верхнем углу видно, что каждая единица кодируется как вложение. Это совершенно логично, потому что каждый из 116 героев Dota 2 может быть классифицирован различными способами:
- Основной атрибут: сила, ловкость, интеллект.
- Тип атаки: дальняя или ближняя.
- Роль: carry, disabler, lane support, initiator, jungler, support, durable, nuker, pusher, escape.
Каждый из этих параметров может формировать измерение в векторе встраивания, и сеть автоматически узнает, насколько каждый герой является носителем, поддержкой или юнглером. Такие же вкрапления применяются к крипам и зданиям, например, башни также имеют дальнобойную атаку. Это очень общий способ представления различных юнитов для сети. Вектор вкрапления конкатенируется с другими атрибутами юнита, такими как здоровье, расстояние до героев и т.д.
Но эмбеддинги используются не только для типов юнитов, они также используются для модификаторов, способностей и предметов.

Image credit: OpenAI.
Опять же, это совершенно логично - хотя способности у всех героев разные, у них есть общие черты, например, нужно ли их активно использовать или они пассивно всегда включены, нужна ли им цель, является ли эта цель другим юнитом или областью и т.д. В случае с предметами некоторые из них лечат, некоторые дают магические способности, некоторые немедленно расходуются, другие повышают ваши показатели. Встраивание - это естественный способ представления вещей с множеством различных, но потенциально пересекающихся качеств, которые могут иметь схожий эффект, но в разной степени.
Обратите внимание, что хотя количество модификаторов, способностей и предметов является переменным, сеть максимизирует каждый из этих списков. Это означает, что только самое высокое значение во всех этих измерениях действительно проходит через сеть. Сначала кажется, что это не имеет смысла - может создаться впечатление, что у вас есть способность, которая является комбинацией всех существующих способностей, например, пассивное исцеление дальнего боя. Но, похоже, это работает.
Вышеописанная обработка выполняется отдельно для каждого из близлежащих юнитов, результаты общих атрибутов, модификаторов героя, способностей и предметов объединяются вместе. Затем применяется различная постобработка в зависимости от того, был ли это вражеский не-герой, союзный не-герой, нейтральный, союзный герой или вражеский герой.
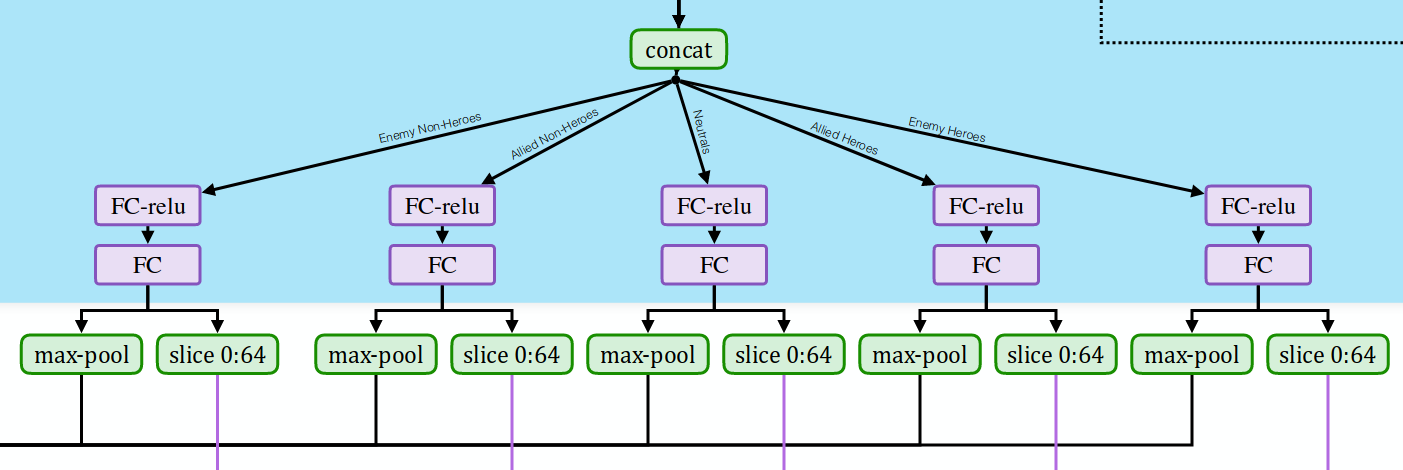
Image credit: OpenAI.
Наконец, результаты постобработки максимально объединяются по всем единицам данного типа. И снова это кажется сомнительным на первый взгляд, потому что различные качества близлежащих единиц будут объединены, например, если одно из измерений будет представлять здоровье единицы, то сети увидят только максимальное здоровье среди единиц одного типа. Но, опять же, похоже, что это работает нормально.
Максимально собранные результаты для каждого из типов юнитов конкатенируются и затем поступают в LSTM. Есть также срезы первой половины вывода, но мы вернемся к этому, когда будем говорить о целях действий.
Встраивание в действия
Пространство действий в Dota 2 оценивается в 170 000 различных действий. Сюда входят обычные действия, такие как перемещение и атака, а также применение способностей, использование предметов, повышение статистики и так далее. Не все действия доступны на каждом временном шаге - возможно, у вас еще нет определенной способности или предмета в инвентаре. Тем не менее, существует около 1000 различных действий, которые вы потенциально можете использовать. Кроме того, многие из этих действий имеют параметры, например, область, куда вы хотите переместиться, или враг, на которого вы хотите нацелиться. И снова OpenAI предлагает красивую визуализацию пространства действий в своем блоге.

Image credit: OpenAI.
Это ставит перед RL огромную проблему исследования, потому что изначально агент начинает просто пробовать случайные действия. Наивным подходом было бы вывести оценки для всех 170 000 действий и ограничить softmax 1000 активными в данный момент действиями. Но OpenAI решил эту проблему с помощью вкраплений и softmax переменной длины.
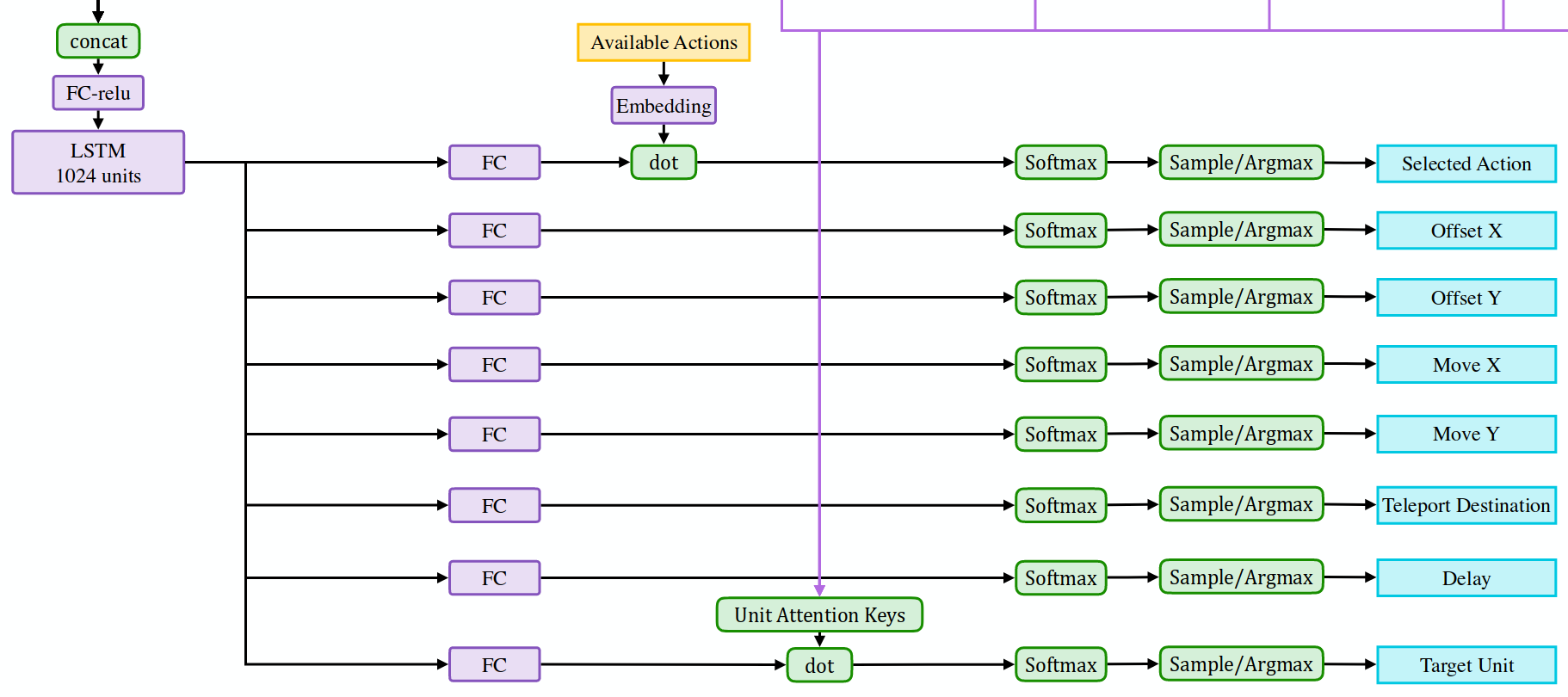
Image credit: OpenAI.
Как вы можете видеть вверху, каждое действие имеет вложение, например, атака с расстояния, использование предмета для лечения или телепортация в определенное место. Точечное произведение вкраплений действий и результатов LSTM используется для получения оценок для различных действий. Эти оценки проходят через softmax, и полученное распределение вероятности используется для выбора одного из доступных действий.
Примечание: точечное произведение между двумя векторами перемножает эти векторы поэлементно и суммирует результат. Иногда его также называют скалярным произведением, поскольку оно дает одно скалярное значение. Оно тесно связано с косинусным сходством - оно имеет тенденцию давать высокие значения, когда векторы направлены в одну сторону, и низкие значения, когда они направлены в противоположные стороны. Он часто используется как быстрый метод оценки сходства двух векторов. Действительно, это именно то, что делает операция свертки - она создает карту сходства между фильтром и входом.

Как я представляю себе выбор действия, LSTM производит нечто, что в принципе можно назвать "вектором намерений". Например, если вы попали в неприятную ситуацию, и уровень вашего здоровья очень низок, то намерение будет что-то вроде "убираться отсюда". Это намерение сопоставляется с доступными действиями и получает высокий балл, если оно совпадает с одним из действий. Например, оба действия "перемещение" и "телепорт" могут быть хорошо согласованы с намерением "выбраться отсюда". Телепорт может быть немного лучше согласован, потому что вас не может преследовать враг, поэтому он дает более высокую оценку и более высокую вероятность после softmax. Но если телепортация недоступна в данный момент, то это встраивание не соответствует, и "двигаться", вероятно, имеет самый высокий балл и вероятность.
Некоторые действия имеют параметры, например, место назначения или цель. Все они моделируются с помощью softmax простым способом. Например, координаты X и Y дискретизируются на диапазоны, вместо того чтобы использовать непрерывные выходы и гауссово распределение. Я полагаю, что softmax лучше справляется с мультимодальными распределениями. Важным наблюдением здесь является то, что выходы действий, похоже, не моделируют совместное распределение между действием и его целью. Я считаю, что это не проблема, потому что все выходы действий обусловлены выходом LSTM. Поэтому выход LSTM уже кодирует "намерение", а эти слои FC просто декодируют различные аспекты этого "намерения" - действие и его цель.
Но больше всего мне нравится то, как OpenAI Five обрабатывает нацеливание. Помните эти странные срезы из выходов наблюдения за единицей? На диаграмме они показаны синим цветом, что означает, что они относятся к единицам. Эти векторы называются "ключами внимания" и сопоставляются с "намерением" LSTM, чтобы получить оценки для каждого блока. Эти оценки проходят через softmax и определяют единицу для атаки. Снова softmax берется по наблюдаемым единицам, точно так же, как softmax действий берется по доступным действиям.
Как я себе это представляю: из наблюдений сеть определяет, что у какого-то юнита очень мало здоровья и у бота есть шанс на last-hit. LSTM вырабатывает намерение "попытка последнего удара", которое хорошо согласуется с действием "атака". Также это намерение "попытка последнего удара" сопоставляется с результатами обработки наблюдений по каждому юниту и хорошо согласуется с юнитом с наименьшим здоровьем. Бах - вы наносите последний удар и получаете дополнительную награду.
Обновление: в более новой версии сети они модулируют выход LSTM вкраплениями действий перед тем, как сделать точечное произведение с ключами внимания юнитов. Я предполагаю, что в противном случае различные действия (например, атака и лечение) пытаются нацелиться на схожих юнитов.
Заключительные слова
После анализа сети OpenAI Five становится ясно, что большая часть сети посвящена восприятию (предварительная обработка наблюдений) и моторному контролю (декодирование действий). Вся стратегия и тактика должна лежать в одном месте - 1024-юнитовом LSTM.
Image credit: OpenAI.
Я думаю, это удивительно, что одна относительно простая математическая конструкция может создать такое сложное поведение. Или, я не знаю, может быть, это говорит о сложности игры Dota 2? Неужели краткосрочная тактика в сочетании с быстрым временем реакции побеждает долгосрочную стратегию?
About MyGpsTools Editorial Team
MyGpsTools publishes practical guides about GPS apps, maps, navigation tools, EXIF photo metadata, satellite imagery, Android Auto, Apple CarPlay, ZIP code maps, and location-based technologies. We focus on clear instructions, practical checks, official documentation, and reader feedback.